Context Engineering for AI Agents - Lessons from Building Manus - AI Agent上下文工程实践经验与核心策略
CN
Click to see a more reader friendly version of this content (点击查看视觉效果更好的版本)
(进入后点击左上角可切换中文)
EN
Context Engineering for AI Agents: Lessons from Building Manus
Key Logic
Yichao 'Peak' Ji, a builder of the Manus project, shared their practical experience and lessons learned in Context Engineering for AI Agents. They emphasized that in the rapidly iterating field of AI, relying on in-context learning and effective context management (rather than training models from scratch) is crucial for rapid product development and decoupling from underlying model technologies. They detailed how sophisticated context design can enhance an agent's performance, efficiency, robustness, and adaptability through six core principles, including optimizing KV-cache, intelligent tool management, using the file system as external memory, actively guiding attention, retaining error information to facilitate learning, and avoiding excessive few-shot techniques.
Designed Around KV-Cache
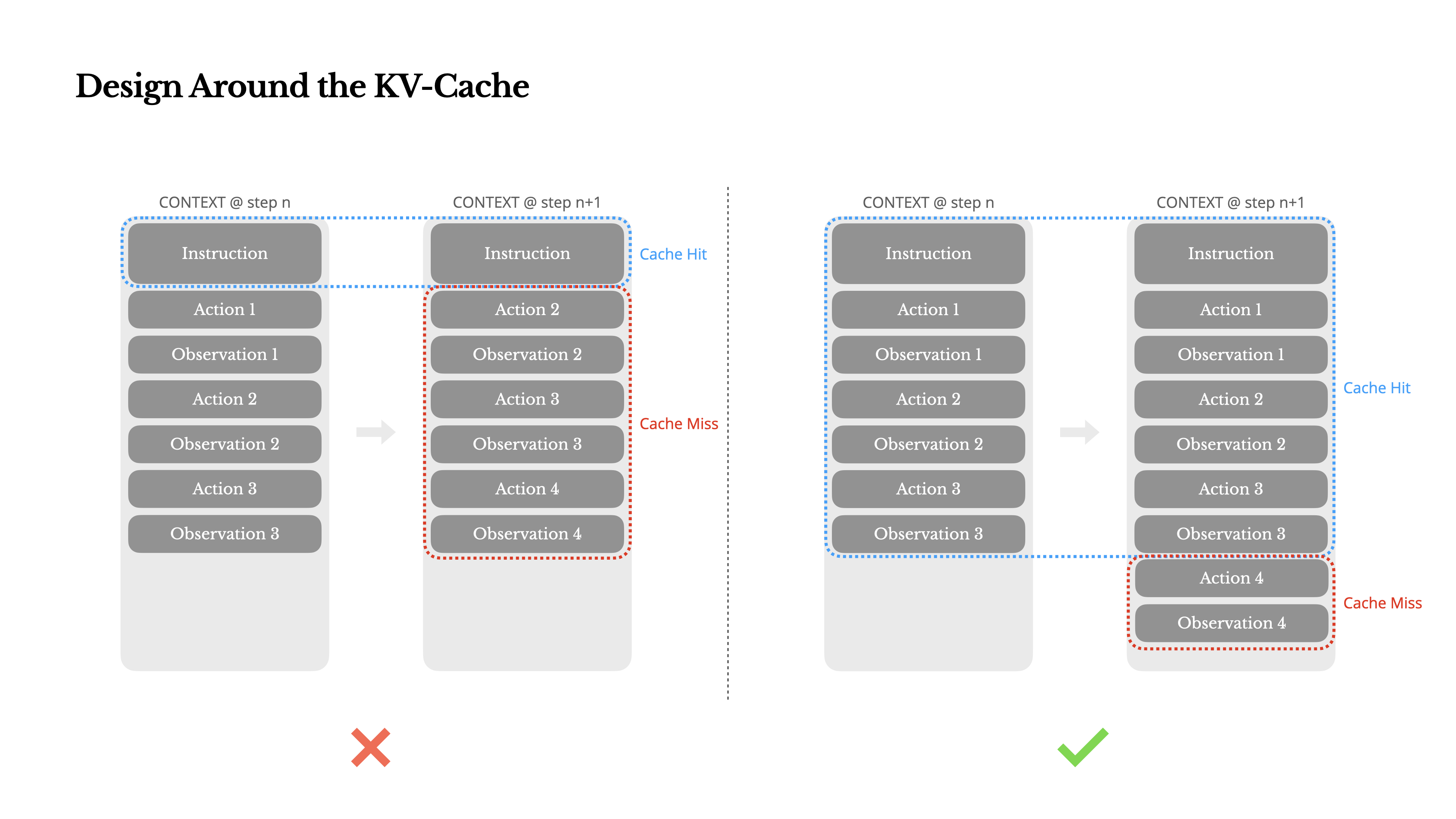
- The author considers KV-cache hit rate to be the most important metric for an AI Agent at the product stage, directly impacting latency and cost.
- The operating mechanism of an agent dictates a highly skewed input-to-output token ratio; for instance, in Manus, the average input-to-output token ratio is approximately 100:1.
- KV-cache significantly reduces time-to-first-token (TTFT) and inference costs by caching identical prefixes.
- Significant Cost-Effectiveness: For example, when using Claude Sonnet, the cost of cached input tokens is $0.30/MTok, whereas uncached tokens are as high as $3/MTok, representing a 10x difference.
- Key practices for improving KV-cache hit rate include:
- Maintaining prompt prefix stability: Even a single token difference can invalidate the cache, such as system prompts containing timestamps precise to the second.
- Ensuring context append-only: Avoiding modification of previous actions or observations.
- Serialization must be deterministic: Many programming languages and libraries do not guarantee stable key order when serializing JSON objects, which can silently break caching.
- Explicitly marking cache breakpoints when necessary: Some model providers or inference frameworks do not support automatic incremental prefix caching, requiring manual insertion.
If self-hosting models, ensure that vLLM and similar frameworks have prefix/prompt caching enabled and utilize a session ID.
Masking, Not Removal
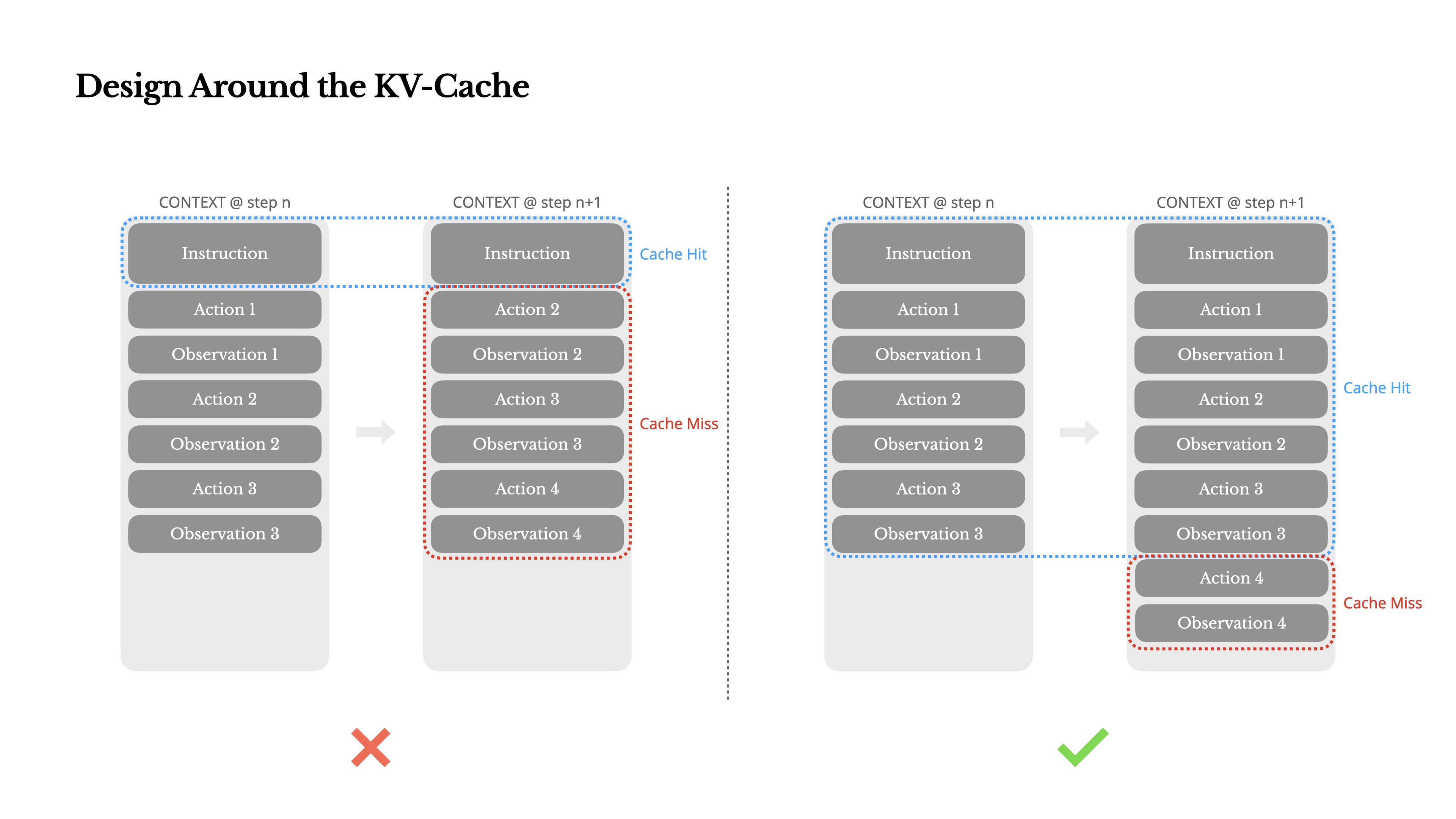
- As agent capabilities continuously improve, their action space becomes increasingly complex, with an explosion in the number of tools. Even allowing user-defined tools can lead to the agent selecting incorrect actions or taking inefficient paths.
- The Manus team experimented with dynamic action spaces but found that, unless absolutely necessary, dynamic addition or removal of tools should be avoided during iteration because:
- Tool definitions are typically at the front of the context, and any change will invalidate the KV-cache for subsequent actions and observations.
- When previous actions and observations still reference tools undefined in the current context, the model becomes confused, potentially leading to schema violation or hallucinated action.
- Manus manages tool availability using a context-aware state machine:
- By masking token logits during the decoding process to block or force the selection of specific actions, rather than removing tools.
- Most model providers and inference frameworks support some form of response prefill, which allows constraining the action space without modifying tool definitions.
- Taking the Hermes format as an example, there are three function calling modes:
Manus also designs action names with consistent prefixes (e.g., all browser-related tools starting with browser_, command-line tools with shell_) to facilitate forcing the agent in a given state.
Using File System as Context
- Modern frontier LLMs have context windows of 128K or more tokens, but this is often insufficient or even burdensome in real-world agentic scenarios, primarily because:
- Observations can be immense; for example, processing unstructured data like web pages or PDFs can easily exceed context limits.
- Even if the context window is technically supported, model performance tends to degrade after a certain context length.
- Long inputs are costly; even with prefix caching, the cost of transmitting and prefilling each token must still be paid.
- To address this issue, many agent systems implement context truncation or compression strategies, but overly aggressive compression inevitably leads to information loss.
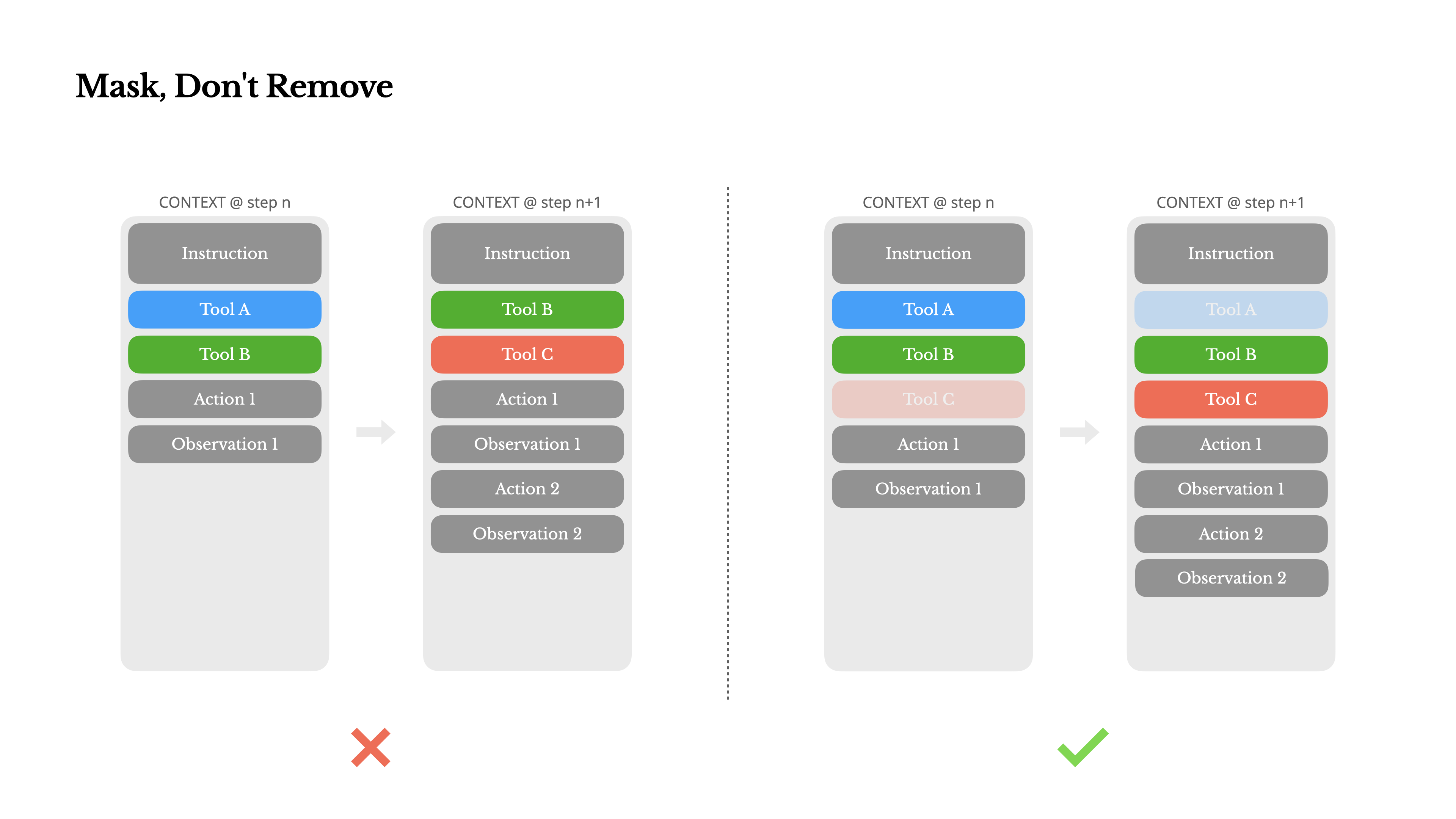
- Manus views the file system as the “ultimate” context:
- Its size is unlimited, it is inherently persistent, and it can be directly manipulated by the agent itself.
- The model learns to read and write files on demand, using the file system not only for storage but also as structured, externalized memory.
- Manus's compression strategies are always recoverable: for example, web page content can be removed from the context as long as the URL is retained; document content can be omitted as long as its path in the sandbox is available.
- In this way, Manus can reduce context length without permanent information loss.
The author also envisions the potential of State Space Models (SSM) in an agentic setting: if SSMs can master file-based memory, externalizing long-term states instead of retaining them in context, their speed and efficiency could be greatly enhanced.
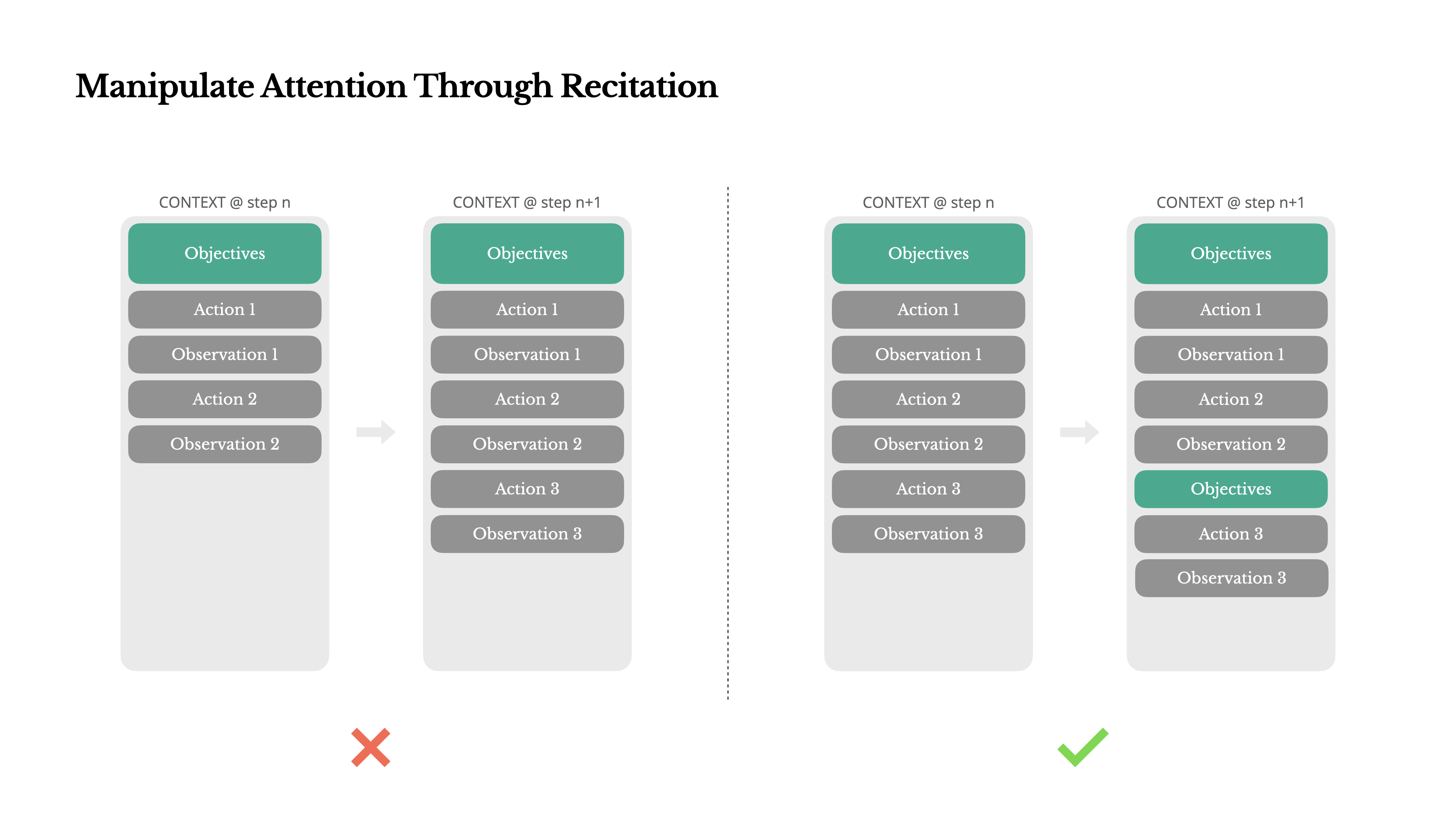
Manipulating Attention Through Reiteration
- When handling complex tasks, Manus tends to create a todo.md file and manipulates attention by progressively updating and checking off completed items.
- This is a deliberate mechanism within Manus:
- In Manus, a typical task requires an average of 50 tool calls, which is a lengthy cycle.
- Because Manus relies on LLMs for decision-making, in long contexts or complex tasks, it often deviates from the subject or forgets early objectives, which are the lost-in-the-middle problem and goal misalignment.
- By continuously rewriting the todo list, Manus reiterates its goals to the end of the context, pushing the global plan into the model's recent attention span.
This practice effectively leverages natural language to bias the model's own focus, without changing the architecture, making it more concentrated on the task.
Retaining Error Information
- It is normal for Agents to make mistakes, not an exception; LLMs can produce hallucinations, environments may return errors, external tools may behave abnormally, and unexpected edge cases always occur.
- In multi-step tasks, failure is part of the loop, not an exception.
- The common impulse for handling errors is to hide them (clean up traces, retry actions, or reset model states), but this comes at a cost: erasing failures eliminates evidence.
- Manus's effective strategy is to retain traces of errors in the context:
- When the model sees a failed action and its resulting observation or stack trace, it implicitly updates its internal beliefs.
- This prevents its prior knowledge from being biased towards similar actions, thereby reducing the chance of repeating the same mistakes.
The author believes that error recovery is one of the clearest indicators of true agentic behavior, but it is often overlooked in most academic work and public benchmarks.

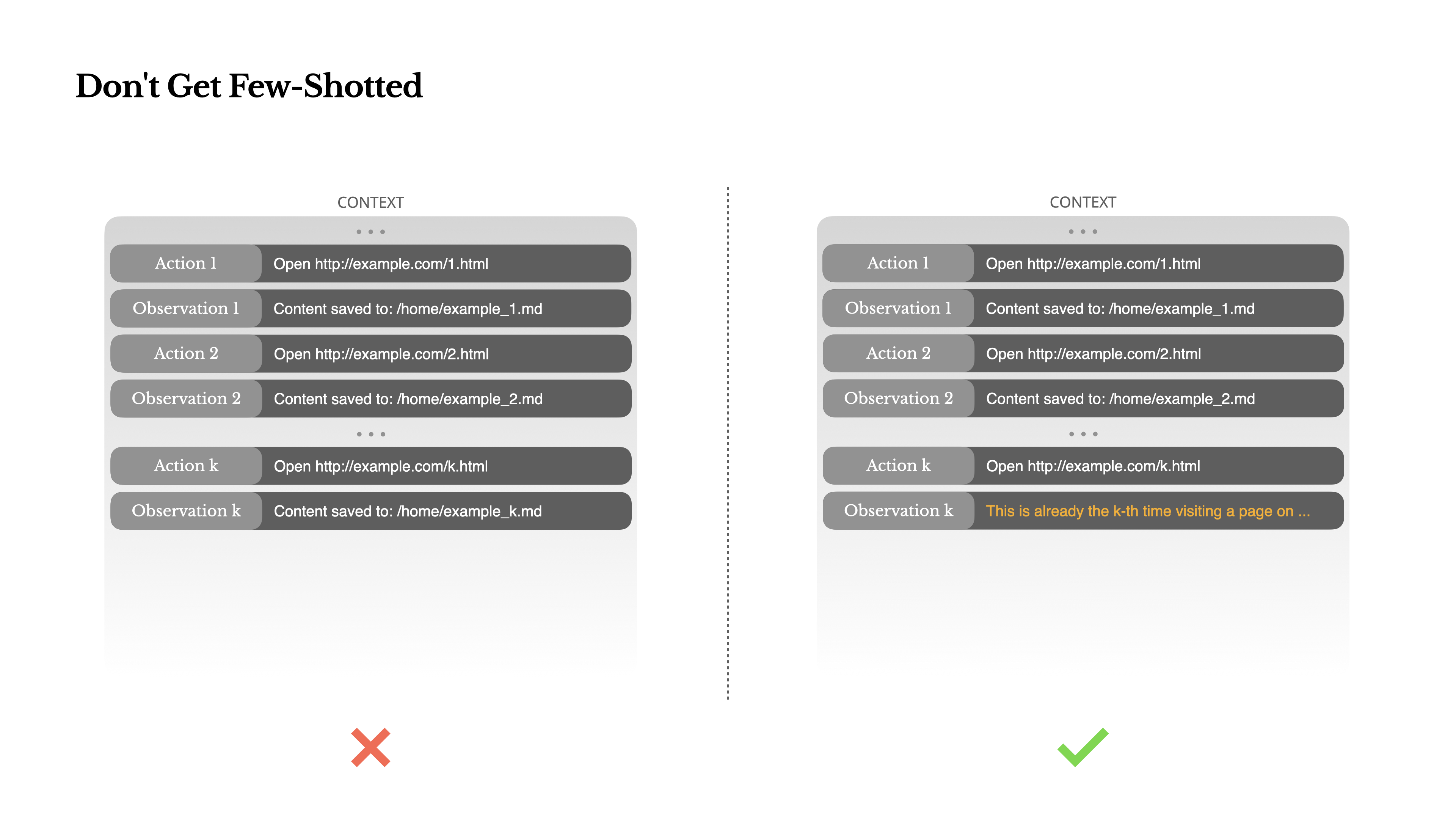
Avoiding the Few-Shot Trap
- Few-shot prompting is a common technique to improve LLM output, but it can be counterproductive in agent systems.
- Language Models (LLMs) are adept at imitation: they mimic behavioral patterns within the context. If the context is filled with similar action-observation pairs, the model will tend to follow that pattern, even if it is no longer optimal.
- This can be dangerous in tasks involving repetitive decisions or actions:
- For example, when Manus assists in reviewing a batch of 20 resumes, the agent often falls into a rhythm, repeating similar actions simply because it observes these patterns in the context.
- This can lead to drift, overgeneralization, or hallucination.
- The solution is to introduce diversity:
- Manus introduces small structured variations in actions and observations, such as different serialization templates, alternate phrasing, and a small amount of sequential or formatting noise.
This controlled randomness helps break patterns and adjust the model's attention, thereby preventing the agent from becoming overly rigid due to an overly uniform context.
#AI_Agent #Context_Engineering #LLM #KV_Cache #Tool_Management #File_System #Attention_Manipulation #Error_Recovery #Few_Shot_Prompting #Manus